We argue that efficient agentic reasoning benefits from decomposing deliberation into three interacting systems: reactive execution (System I) for fine-grained reasoning and direct action; simulative reasoning (System II) that predicts consequences of proposed actions through a world model, providing a unified planning mechanism across diverse tasks; and self-regulation (System III) that decides when and how deeply to plan through a learned configurator.
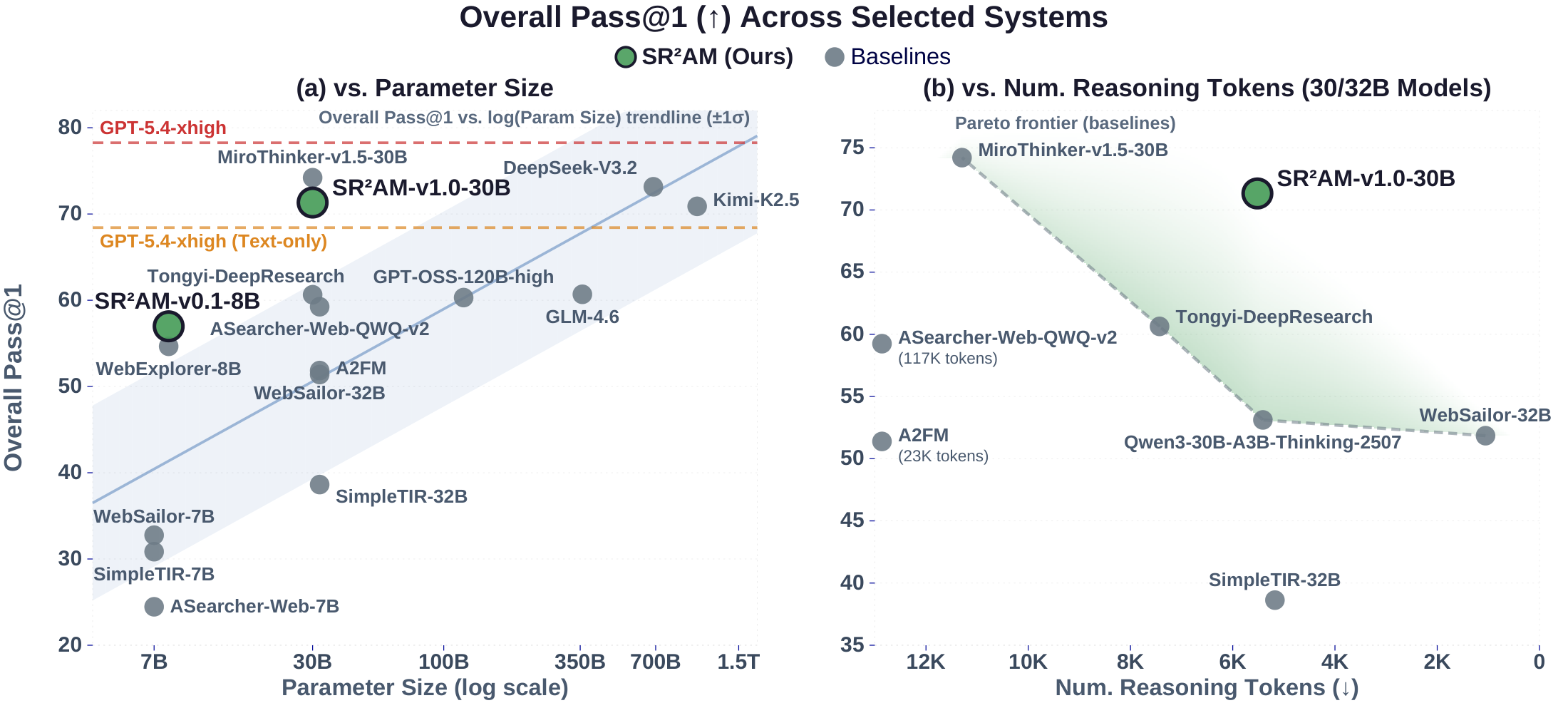
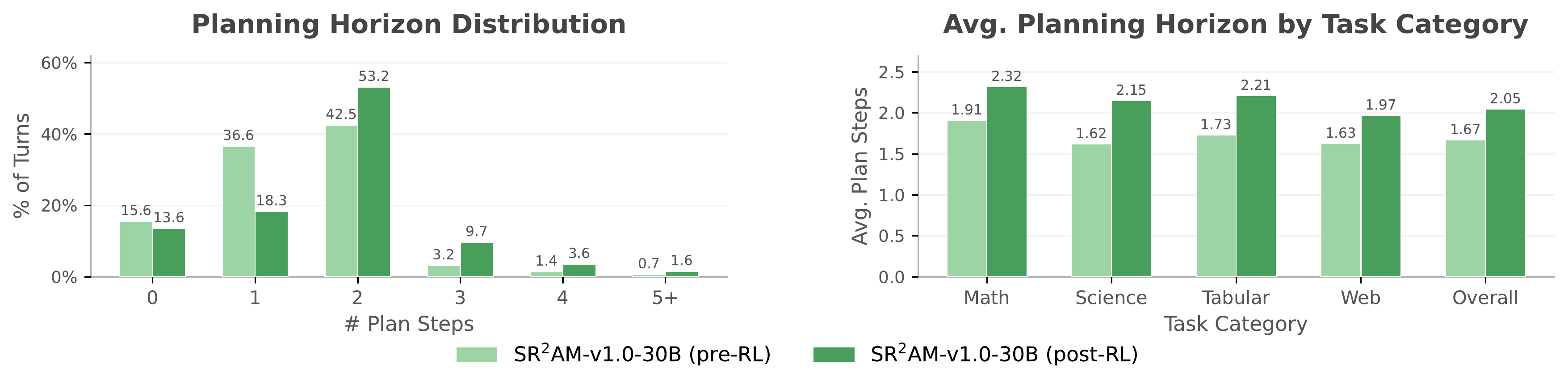
SR2AM (Self-Regulated Simulative Reasoning Agentic LLM) is our instantiation of this decomposition: the configurator and simulative planner are realized as distinct stages within an LLM's chain-of-thought reasoning, with the LLM itself serving as the world model in language space. By separating self-regulation, planning, and execution while preserving the expressiveness of free-form reasoning, SR2AM learns to plan further ahead rather than simply reason more, achieving competitive task performance with substantially fewer reasoning tokens.
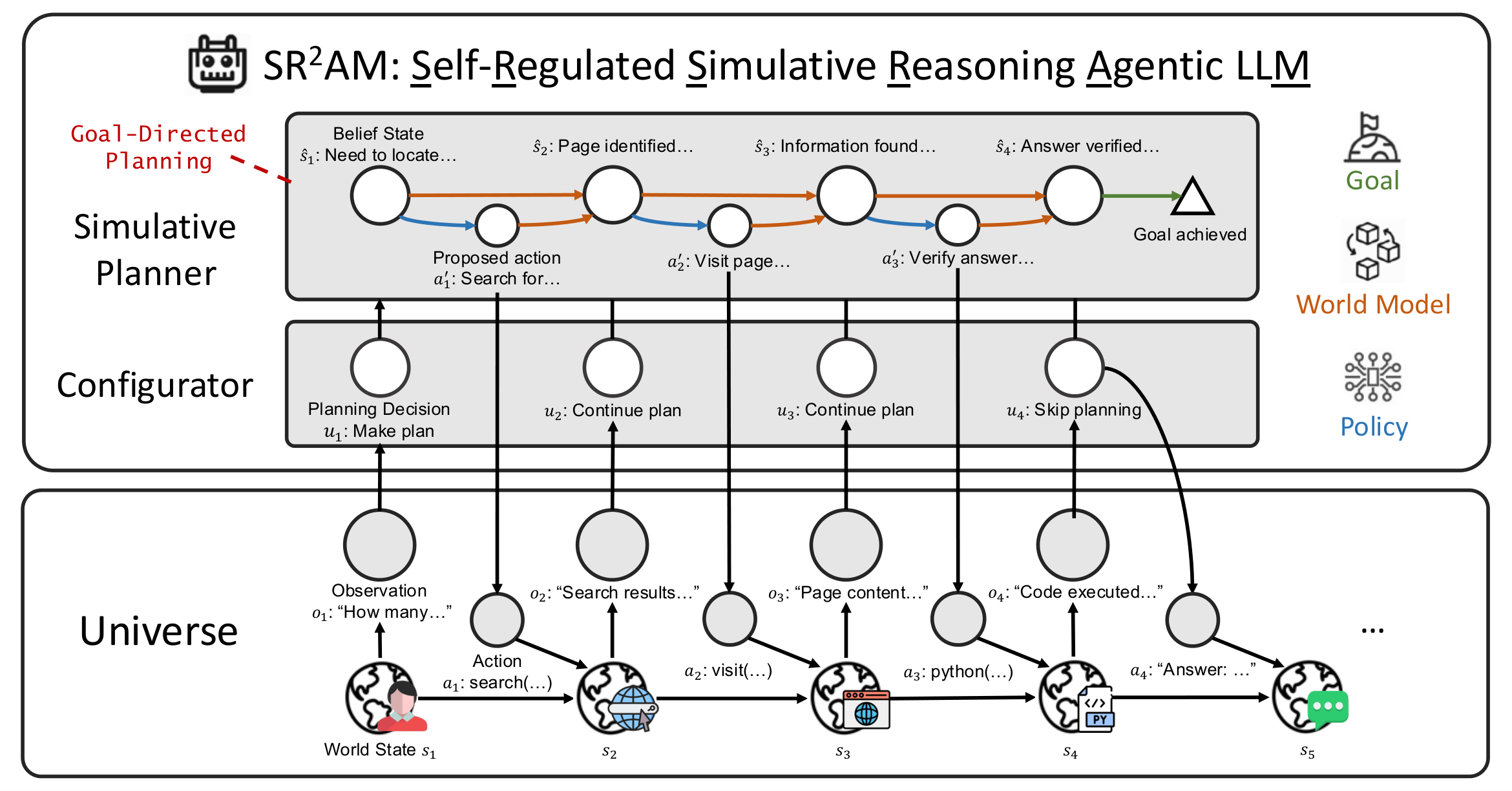
SR2AM at each turn: the configurator (System III) decides whether to make a plan, continue an existing one, or skip planning; when invoked, the simulative planner (System II) generates structured proposed actions and predicted future states using the LLM as a world model; the actor (System I) then executes via free-form reasoning and tool use.